2021. 7. 19. 02:42ㆍ코드스테이츠
W5L2
Kaggle 등의 기존 데이터를 분석해 유의미한 결과 발견하기
기존 데이터 셋을 활용해 데이터 분석 프로젝트를 수행하고 유의미한 결과 찾아내는 과정을 정리합니다.
제품에서 직접 얻은 데이터는 아니지만, 데이터와 제품을 바라보는 시각과 데이터를 실제로 다뤄 결과를 도출해 내는 실무 능력을 모두 보여줄 수 있습니다.
내가 코드스테이츠 교육을 수료하고 PM으로 들어가게 될 회사는 스타트업일 수도 있다. 큰 회사가 아니라면 보유하고 있는 데이터는 어쩔 수 없이 한정적일 수 밖에 없다. 회사에 존재하는 내부데이터에서 우리 고객의 인사이트를 얻어내는 것도 필요하지만 더욱 넓은 시장에서 인사이트를 찾고 새로운 기회를 발굴하기 위해 내부데이터가 아닌 외부데이터를 찾아 데이터분석을 진행해야할 필요가 있을 것이다. 외부데이터를 얻을 수 있는 대표적인 공개 사이트로 Kaggle, Dacon, 공공데이터포털이 있다.
오늘은 데이터 분석 체험을 해보기 위해 위 사이트에서 직접 데이터를 하나 가져와서 살펴보고자 한다. 찾고자 하는 데이터의 주제는 내가 좋아하는 커피다. '공개되어 있는 공간안에서 내가 원하고 관심있어하는 인사이트를 뽑아내기 위해서 과연 얼마나 많은 데이터를 찾을 수 있을까'라는 고민과 함께 데이터를 둘러보기를 시작했다.

그런데 어떤 데이터를 살펴봐야 하는걸까?
우선 나는 커피와 카페에 관련된 데이터를 찾고 싶었다. 커피를 좋아해서 커피, 카페와 관련된 서비스를 만들고 싶다는 생각을 막연히 품고 있었는데, 이번 기회에 관련된 인사이트를 찾으면 어떤 서비스가 사람들의 커피라이프에서의 불편함을 해소할 수 있을지 찾아볼 수 있을 것 같았다.
나는 사람들이 본인의 취향에 맞는 커피를 좋아하는 공간에서 맛있게 즐길 수 있기를 바란다. 이 목적을 달성하기 위해서는 커피를 생산하는 시스템을 분석해봐도 좋겠지만 커피를 소비하는 사람들 즉, '고객' 관점을 더욱 집중해서 분석할 필요가 있다고 생각했다. 사람들이 카페에 왜 가는지, 어떤 과정을 통해서 카페를 선택하는지, 어떤 커피를 마시는지, 그 커피를 선택한 이유는 뭔지, 얼마나 자주 커피를 구매하는지, JTBD관점에서 어떤 과업을 달성하기 위해 그 커피를 선택(채용)했는지, 더 좋은 카페 경험을 위해서 무엇이 필요한지 등을 알고 싶었다.
그런데 위의 정보를 알기위해 어떤 데이터를 봐야 하는건지 감이 잘 잡히지 않았다. 고객의 직업에 따른 카페메뉴 선호도, 2021년 상반기 서울지역의 20대가 많이 방문하는 카페리스트, 등산로 근처 카페의 고객연령대와 메뉴분석, 프랜차이즈와 로컬카페의 시장규모, 카페경험 퍼널 등의 데이터를 볼 수 있으면 좋겠지만 공개된 사이트에 그런 데이터가 있을까? 실제로 그 데이터들이 내가 원하는 인사이트를 찾을 수 있는 데이터인것은 맞을까? 위의 예시와 유사한 데이터라도 얻을 수 있기를, 희미한 단서라도 발견할 수 있기를 바라며 일단 사이트를 뒤져보기 시작했다.
데이터 사이트 둘러보기
Dacon
데이콘은 데이터사이언스 컴피티션 플랫폼이다. 기업에서 데이터를 데이콘에 의뢰하면 데이콘에서 솔루션을 검증하는 대회를 열어서 여러 참가자들이 자신만의 방법으로 데이터를 분석하고 솔루션으로 경쟁한다. 이 과정에서 대회를 진행하기위해 데이터가 제공되는데 데이터분석을 처음 시작하는 사람들은 쉽게 얻기 힘든 다양한 데이터를 찾아볼 수 있고, 대회에 참가한 전문가들이 분석한 내용을 보고 공부를 할 수도 있다. 무엇보다 좋은 점은 한국서비스라서 !!!!한국어!!!!로 이루어져 있다는 것. IT 서비스에 대해 공부를 하다보면 영어의 장벽에 여러번 얻어맞는 것 같은 느낌이 들때가 많다. 한국어로 되어있다는 것만으로도 입문자에게는 단비같은 서비스가 아닐 수 없다. 하지만 아쉬운 부분도 있는데 2018년에 만들어진 서비스라서 아직 쌓인 데이터가 많지는 않다는 점 이었다. 계속 점점 더 많은 데이터대회를 개최하고 있기때문에 앞으로 더 많은 데이터가 쌓일 것이라 생각하지만 내게 필요한 커피와 카페에 관련된 데이터는 거의 찾아볼 수 없어서 이번에는 활용하기가 어려웠다.
공공데이터포털
공공데이터포털은 대한민국 정부에서 보유하고 있는 다양한 공공데이터를 공개하고 제공하는 서비스이다. 당연히 한국어로 이루어져있고, 공공기관이 보유한 데이터이기 때문에 개인 단위의 데이터는 배제된 것이 대부분이다. 특정 지역에 몇개의 카페가 있는지는 알 수 있지만 어떤 특징을 가진 고객이 이용하는지 등의 고객관점 데이터를 얻기는 어렵다. 따라서 이 사이트에서도 쓸만한 데이터를 찾거나 활용하기는 어려웠다.
Kaggle
캐글은 데이콘처럼 데이터분석 경진대회를 주최하는 플랫폼이다. 데이콘처럼 기업에서 데이터를 받아서 대회를 열고 참가자나 서비스 사용자가 데이터에 접근할 수 있다. 해외서비스이고 영어를 사용하지만 전세계적으로 규모가 있는 서비스라서 정말 많은 데이터를 찾아볼 수 있다는 장점이 있다. coffee나 cafe에 관련된 데이터도 많았다. 여기에서는 참고해볼만한 데이터를 찾아볼 수 있을 것 같다. 이제 남은 것은 파파고와 함께 하는 집요한 탐험뿐...
분석할 데이터 선정
캐글에서 마음에 드는 데이터를 2가지 찾았다. 하나는 Yelp라는 맛집 어플의 커피리뷰라서 실제로 내가 원하는 인사이트를 발견할 가능성이 있는 데이터였고, 나머지 하나는 가상의 커피체인점의 소매 데이터를 만든 데이터였다. 가상의 데이터는 9개의 csv 파일로 구성되어있었고 확실한 관계형 데이터베이스여서 연습을 해보기에 좋은 데이터였다. 이중에서 나는 조금 더 최근 자료이고, 실제 데이터이며, 내가 원하는 서비스와 유사한 장점을 가지고 있는 Yelp coffee review의 데이터를 탐색해보기로 했다.
https://www.kaggle.com/sripaadsrinivasan/yelp-coffee-reviews
Yelp Coffee Reviews
Yelp Coffee Shop Reviews ☕☕☕
www.kaggle.com
데이터 정보 파악하기
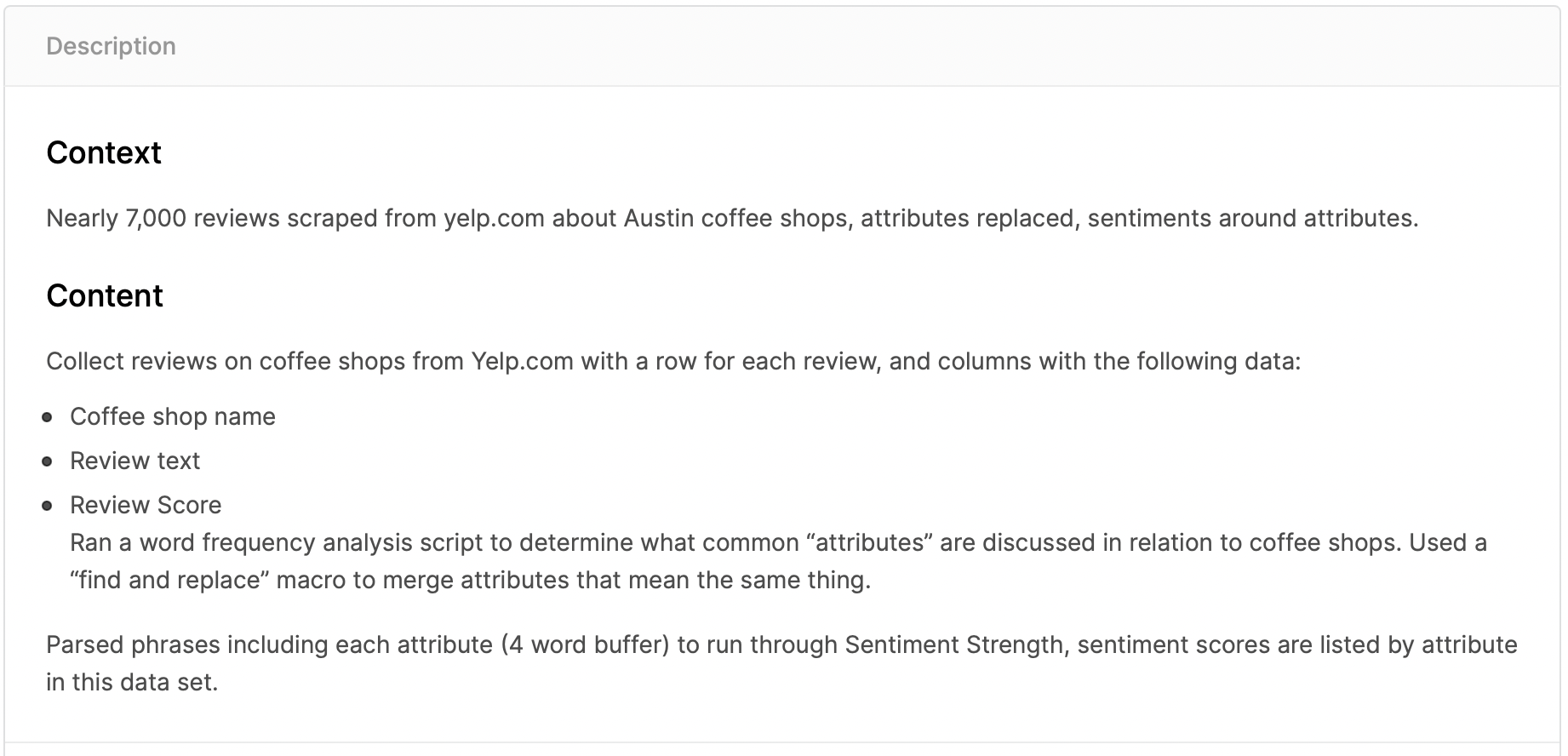
캐글에서 데이터셋을 골라서 클릭하면 상단에 Description이 첫번째로 나와서 데이터에 대한 개요를 파악할 수 있다. 다만 데이터마다 설명에는 차이가 있다. 코드스테이츠의 과제에서 추천해주신 브라질 이커머스 데이터는 굉장히 상세하게 설명되어 있었는데 Yelp coffee review는 간단하게 작성되어 있는 편이다. Description을 토대로 간단하게 데이터 개요를 정리해보았다.
- 개요 : Yelp.com 에 작성된 미국 오스틴 지역 커피숍에 대한 약 7000개의 리뷰
- 데이터특성 : 커피숍이름, 리뷰글, 리뷰점수 로우데이터가 있으며, 단어빈도분석 스크립트를 이용해 커피숍의 특성을 추출한다
- 데이터구조 : 각 특성을 포함하는 구문 분석된 문구로, 감성 점수는 이 데이터 세트에 속성별로 나열된다 (이 부분은 파파고 번역을 그대로 가져왔는데, 단어빈도분석을 통해 추출된 문구를 속성별로 묶어서 나열한다고 이해했다)
DB 스키마 작성하기
이전에 w3schools의 데이터를 draw.io 사이트를 이용하여 스키마를 ERD 형식으로 작성해봤던 것처럼 Yelp의 데이터도 스키마를 ERD형식으로 작성해보았다.

보면 알겠지만 구조가 단순하다. Yelp Coffee 에서 제공한 csv 파일은 세가지였는데 하나는 커피숍, 리뷰, 별점이 포함된 로우데이터 였고 나머지 두개는 로우데이터를 기반으로 속성별 평가점수와 감상점수가 추가된 정보인 것 같다.
위 데이터를 토대로 사람들이 평가를 하는 주요 감성평가 항목, 특정 커피숍에 대한 평가 점수, rating 점수가 높은 커피숍의 장점 파악 등을 알 수 있다. 예를 들어 sentiments by shop 데이터를 보면 사람들은 커피숍에 대한 감성평가 항목으로 커피, 티, 분위기, 인터넷, 음식, 술, 좌석을 기준으로 선정된다는 것을 알 수 있고 각 항목에서 좋은 점수를 받은 매장을 추려서 텍스트 분석을 해보면 고객이 해당 매장을 찾게 되는 주요 원인과 니즈를 분석할 수 있다. 그리고 더 나아가서 매장별 포지셔닝 분포도를 파악하여 니즈에 따라 카페를 찾는 사람들에게 맞춤 카페를 제안하는 등 좀 더 개인화된 마케팅을 펼칠 수도 있을 것이다.
실제 데이터 살펴보기
리뷰 로우데이터 (raw yelp review data)

- 총 리뷰 수 7616개 = Valid(유효),Mismatched(비유효),Missing(유실) 세가지 수를 합한다.
- Yelp 서비스 내에서 가장 많이 언급된 오스틴커피숍은 Epoch Coffee = Most Common을 보면 가장 많이 언급된 것을 알 수 있다.
평가점수와 감성점수 (ratings and sentiments)
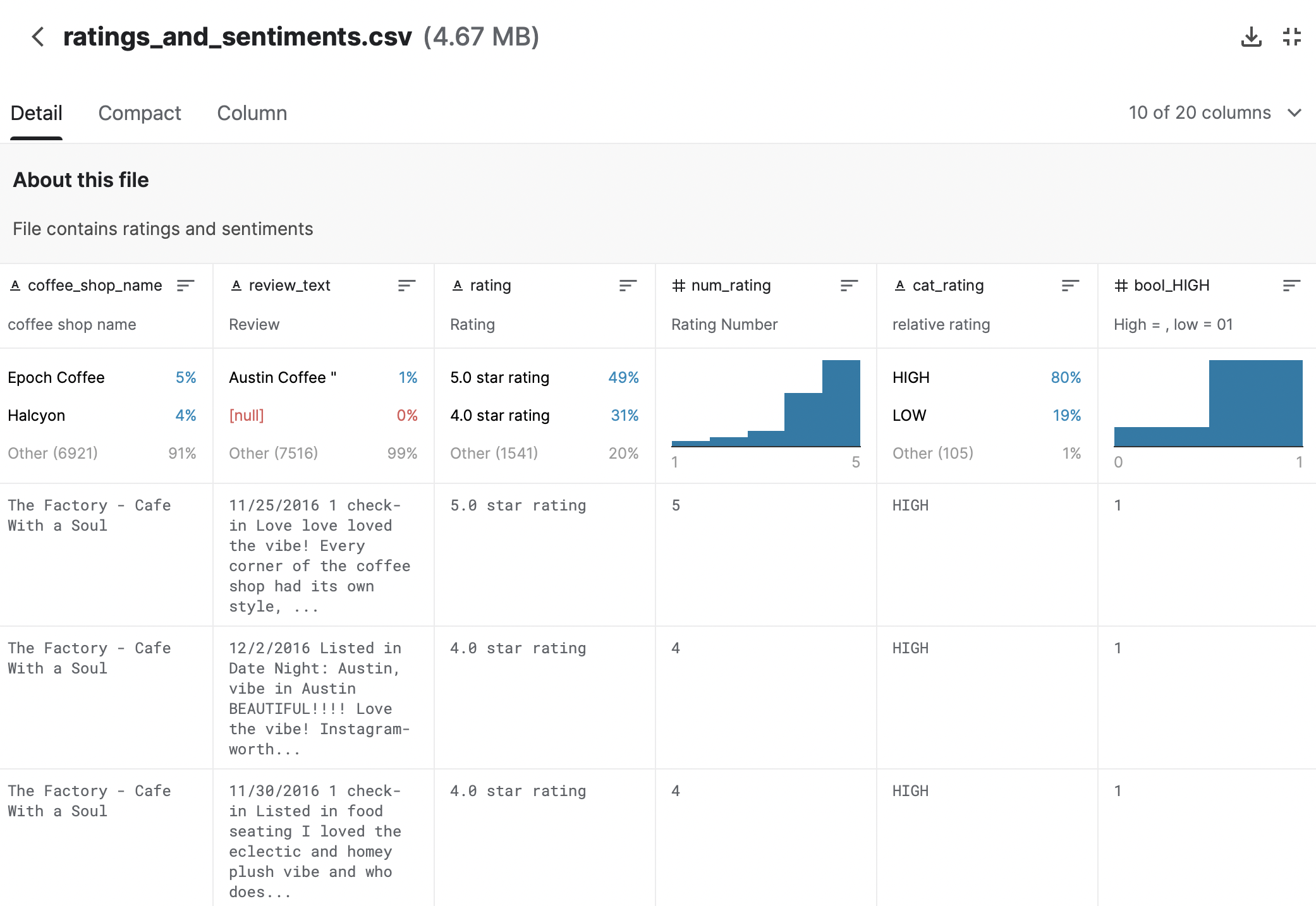

- 커피숍, 리뷰, 평가점수, 감성점수를 전반적으로 한눈에 볼 수 있는 데이터 테이블이다.
- 상대적으로 높은 평점이 많다. = 상대적 등급을 활용하여 4점 이상은 HIGH를 부여했으며, HIGH가 80%다.
- 전체적인 감성점수는 평균적으로 높으나 낮은 점수도 일부 존재한다. = 데이터 시각화 그래프가 우측으로 편중되어 있음을 보고 알 수 있다.
- 분위기, 티, 서비스에 대한 감성점수는 중간정도이다. = 데이터 시각화가 상단에 기재되어 있으며 중간 평점의 영역이 가장 많다.
가게별 감성점수 (sentiments by shop)
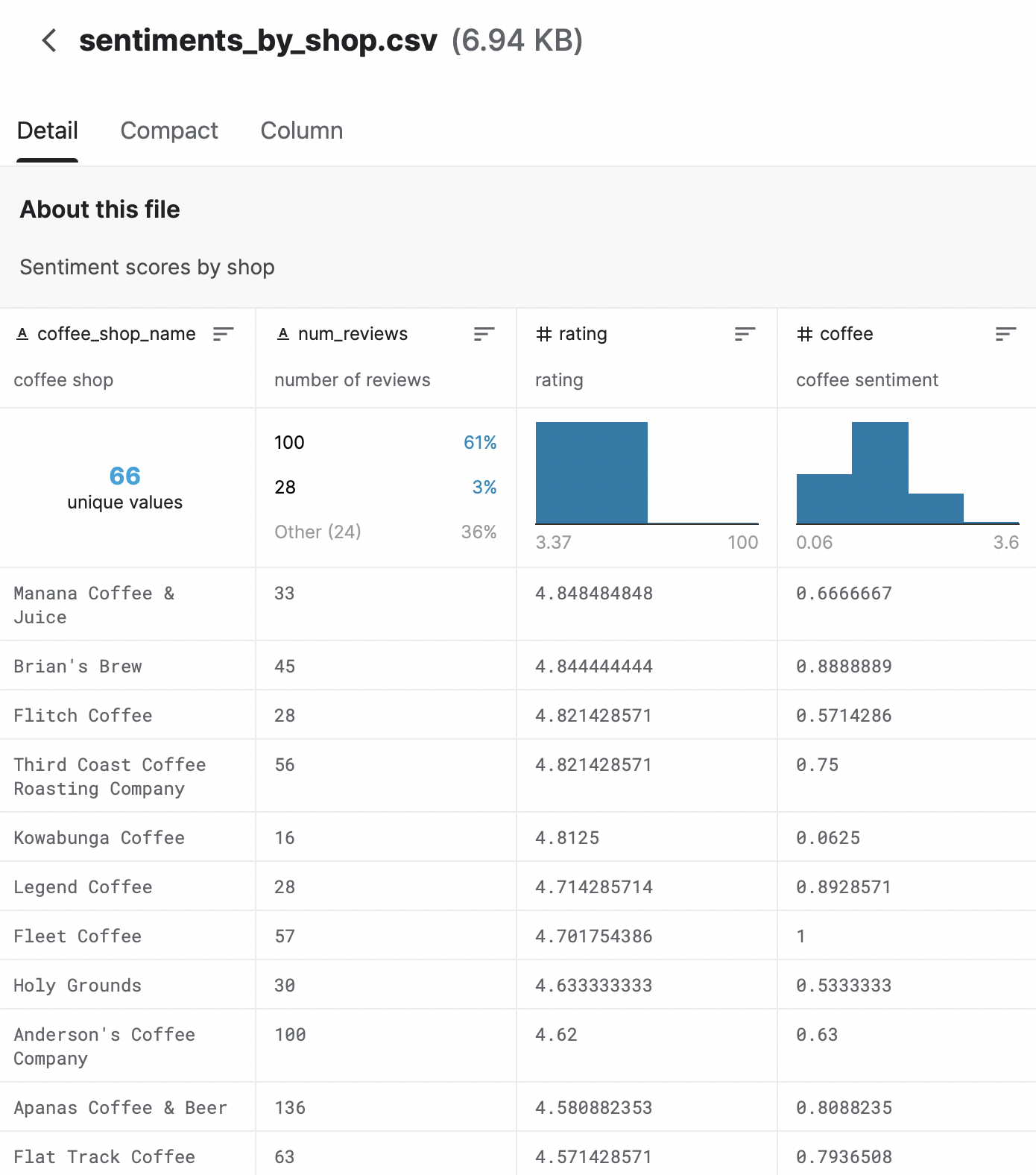
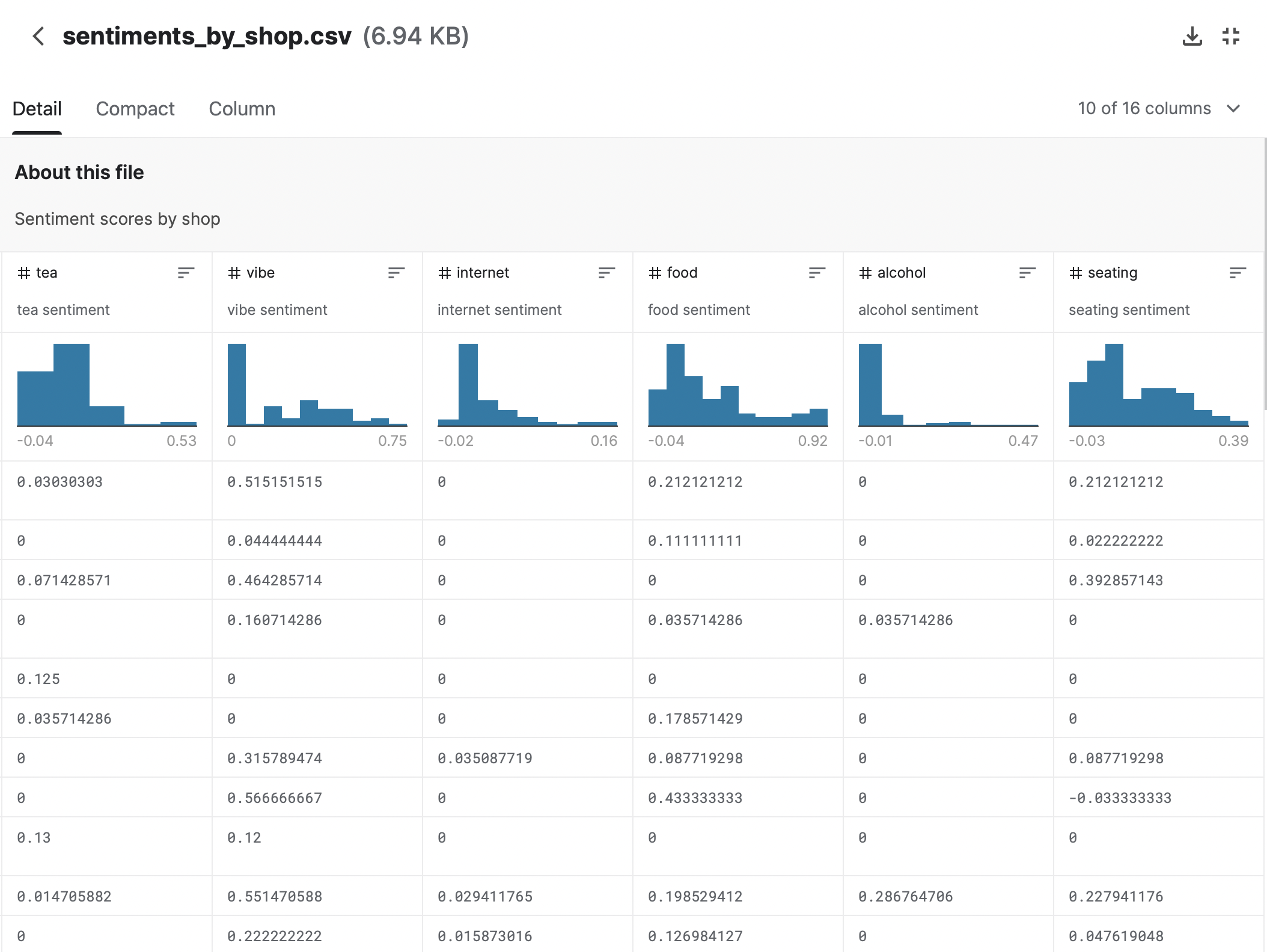
- 가게 별로 점수를 취합하여 감성적인 항목에 대해 점수를 확인할 수 있는 데이터 테이블이다.
- 가게 수는 총 66개 = coffee shop 항목 아래에 unique values를 보면 알 수 있다.
- 100개의 리뷰수를 확보한 업체가 61% = 일정 수준 이상의 리뷰수를 확보하면 데이터의 신뢰도가 올라간다.
- 분위기, 인터넷, 알콜 부분에서 높은 점수를 받은 업체가 별로 없다. = 해당 부분을 강화하는게 하나의 차별화 전략이 될 수 있다.
- 카페를 평가할 때 인터넷이나 좌석같은 사용자 경험과 관련된 데이터도 평가지표 중 하나이다. = 카페를 단순히 음료나 음식을 파는 업체로 한정하는게 아니라 경험을 제공하는 공간으로서 판단해야 한다.
다른 사람들은 이 데이터를 어떻게 보고 있을까
다른 사람이 이 데이터를 어떻게 보는지 궁금했는데 생성된지 오래된 데이터가 아니어서인지는 몰라도 토론글은 하나도 없었고 코드만 2개 있었다. 그중에 한분의 분석에서 재미있는 인사이트를 가지고와봤다.
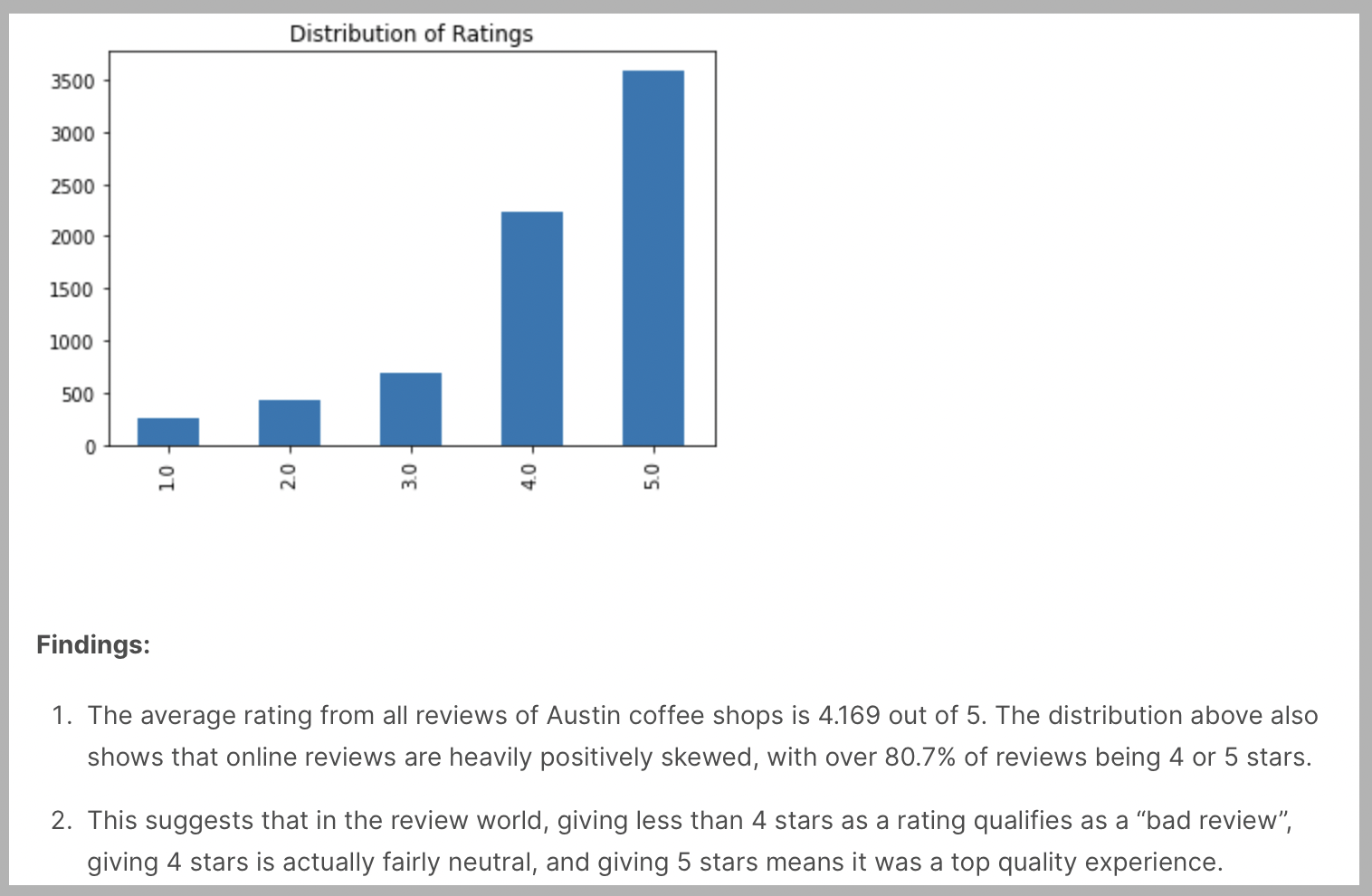
이미지 속 소견 부분에 대한 내용을 대충 해석해서 요약해보면 아래와 같다.
"4점과 5점이 합쳐서 80%라는건 타당성이 부족하고 왜곡된 데이터로 볼 수 있다. 따라서 4점 미만은 '나쁨', 4점은 '보통', 5점은 '좋음'으로 판단해야 한다."
고객들은 서비스에 대한 평점을 내릴 때 웬만하면 좋은 쪽으로 점수를 주려한다는 경향이 있다는 글을 읽은 적이 있다. 심리학적인 부분이 적용된 내용이었는데 그 글과 위 데이터를 비교해자보면, 사람들은 기본적으로 높은 점수를 주려하는 경향이 있기때문에 데이터를 분석할 때 그 부분을 고려해서 중간에 해당하는 지점을 높게 잡아서 평점에 대한 인사이트를 찾아야 한다고 볼 수 있다.
실제 이 분석글을 보면 긍정적으로 왜곡되어 있다는 부분을 데이터분석을 통해서 단계적으로 풀어서 설명한다. 자세한 분석과정을 보고 싶다면 참고자료 5번에서 확인할 수 있다.
나는 어떤 데이터 분석을 해보고, 어떻게 포트폴리오에 적용할 수 있을까
일단 나는 데이터분석에 필요한 툴 중에서 사용할 수 있는게 하나도 없다. 분석을 위해 간단하게라도 데이터를 분석하고 추출할 수 있는 언어를 배울 필요가 있다. 배워보고 싶은 것은 SQL과 파이썬 2가지다.
위의 예시로 든 데이터 분석도 파이썬을 통해서 이루어졌는데 파이썬은 배워두면 꼭 데이터분석에만 쓰는게 아니라 다양하게 활용할 수 있고, SQL은 DBMS 위주로만 사용되겠지만 최근 취업시장에서의 수요가 높은 스킬 중에 하나라서 둘 다 높은 효용성을 가지리라 생각한다.나는 업무자동화와 시스템화도 관심이 많아서 우선 파이썬을 조금씩 배워보려고 한다.
그리고 yelp review를 분석해서 코드스테이츠 프로젝트에 적용해보면 좋을 것 같다. 내가 찾고자 하는 정보는 고객이 카페를 선택하는 기준과 이유다. 텍스트리뷰의 단어빈도분석을 통해서 카페의 어떤 특성이 고객의 니즈에 부합했는지 찾아보고 각 특성을 프로젝트 서비스에 적용하여 고객이 카페를 선택하는데 도움이 될 수 있도록 하고자 한다.
내가 세운 가설은 아래와 같다.
'고객은 카페를 선택할 때 저마다의 기준이 있으며 그 기준을 가이드로 안내해주면 더욱 쉽게, 더욱 자주 카페를 이용하게 될 것이고 카페 경험이 더욱 긍정적으로 변화할 것 이다.'
위 가설을 검증하기 위해 yelp review의 데이터는 솔루션 검증단계에서 서비스를 구성하기 위한 목적으로 사용하고자 한다.
[참고자료]
1. https://www.kaggle.com/ylchang/coffee-shop-sample-data-1113
Coffee shop sample data (11.1.3+)
IBM Cognos Analytics sample data sets
www.kaggle.com
2. https://www.kaggle.com/sripaadsrinivasan/yelp-coffee-reviews
Yelp Coffee Reviews
Yelp Coffee Shop Reviews ☕☕☕
www.kaggle.com
3. https://blog.naver.com/mqday/221715447491
'데이콘의 대표' 김국진을 만나다..
'데이콘의 대표' 김국진을 만나다.. 사회와 기업 그리고 개인들의 도움이 되는 선순환 구조의 비...
blog.naver.com
4. https://velog.io/@kwonhl0211/Hello-Kaggle-캐글이-처음인-분들을-위한-캐글-가이드
Hello Kaggle! 캐글이 처음인 분들을 위한 캐글 가이드
Hello Kaggle은 제가 직접 작성한 문서이며 아래는 문서의 깃허브 레포지터리 링크입니다. 만약 Hello Kaggle이 도움이 되셨다면 🌟 꾸욱 눌러주시면 감사하겠습니다!
velog.io
5. https://www.kaggle.com/sripaadsrinivasan/yelp-coffee-shop-reviews-analysis
Yelp Coffee Shop Reviews Analysis
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
'코드스테이츠' 카테고리의 다른 글
| [코드스테이츠 PMB 7기] 피그마로 네이버지도를 그려보자 (0) | 2021.08.05 |
|---|---|
| [코드스테이츠 PMB 7기] 카카오톡을 Laws of UX 관점에서 이해하기 (0) | 2021.07.25 |
| [코드스테이츠 PMB 7기] SQL 맛보기 (0) | 2021.07.08 |
| [코드스테이츠 PMB 7기] 루티너리에 A/B 테스트를 진행해본다면? (0) | 2021.07.01 |
| [코드스테이츠 PMB 7기] 프레시코드는 Growth Point를 찾았을까? (0) | 2021.06.29 |